-
[PlayData - Day 12] 파이썬으로 엑셀 파일 다루기[플레이데이터] 2023. 1. 6. 12:15
1. K-Digital Training 과정
- 빅데이터 기반 지능형SW 및 MLOps 개발자 양성과정 19기 (2023/01/05 - Day 12)
2. 목차
- 엑셀 파일을 읽고 쓰기
- 엑셀 파일 통합하기
- 엑셀 파일로 읽어온 데이터 다루기
- 엑셀 데이터의 시각화
3. 수업 내용
1. 엑셀 파일을 읽고 쓰기
엑셀 파일의 데이터 읽기
pandas로 엑셀파일 데이터 읽기
df = pd.read_excel('excel_file.xlsx'[, sheet_name = number 혹은 '시트이름'], index_col = number 혹은 '열이름')import pandas as pd df = pd.read_excel('C:/myPyCode/data/학생시험성적.xlsx') df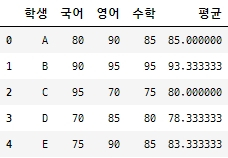
A = ['A', 80, 90, 85] B = ['B', 90, 95, 95] C = ['C', 95, 70, 75] D = ['D', 70, 85, 80] E = ['E', 75, 90, 85] df = pd.DataFrame([A, B, C, D, E], columns=['학생','국어','영어','수학']) df['평균'] = round(df[['국어','영어','수학']].mean(axis = 1),2) df = df.set_index('학생') df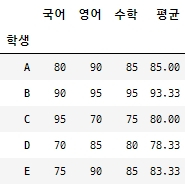
pd.read_excel('C:/myPyCode/data/학생시험성적.xlsx', sheet_name=1)학생 과학 사회 역사 평균 0 A 90 95 85 90.000000 1 B 85 90 80 85.000000 2 C 70 80 75 75.000000 3 D 75 90 100 88.333333 4 E 90 80 90 86.666667 pd.read_excel('C:/myPyCode/data/학생시험성적.xlsx', sheet_name='2차시험')학생 과학 사회 역사 평균 0 A 90 95 85 90.000000 1 B 85 90 80 85.000000 2 C 70 80 75 75.000000 3 D 75 90 100 88.333333 4 E 90 80 90 86.666667 df = pd.read_excel('C:/myPyCode/data/학생시험성적.xlsx', sheet_name='2차시험', index_col = 0) df과학 사회 역사 평균 학생 A 90 95 85 90.000000 B 85 90 80 85.000000 C 70 80 75 75.000000 D 75 90 100 88.333333 E 90 80 90 86.666667 엑셀 파일로 쓸 객체를 생성
excel_exam_data1 = {'학생':['A', 'B', 'C', 'D', 'E', 'F'], '국어': [80, 90, 95, 70, 75, 85], '영어': [90, 95, 70, 85, 90, 95], '수학': [85, 95, 75, 80, 85, 100]} df1 = pd.DataFrame(excel_exam_data1, columns = ['학생', '국어', '영어', '수학']) df1학생 국어 영어 수학 0 A 80 90 85 1 B 90 95 95 2 C 95 70 75 3 D 70 85 80 4 E 75 90 85 5 F 85 95 100 데이터를 쓸 엑셀 시트 쓰기
excel_writer = pd.ExcelWriter('C:/myPyCode/data/학생시험성적2.xlsx', engine='xlsxwriter') df1.to_excel(excel_writer, index=False) excel_writer.save()시트 이름을 지정하여 저장하기
excel_writer2 = pd.ExcelWriter('C:/myPyCode/data/학생시험성적3.xlsx', engine='xlsxwriter') df1.to_excel(excel_writer2, index=False, sheet_name='중간고사') excel_writer2.save()2. 엑셀 파일 통합하기
excel_exam_data2 = {'학생': ['A', 'B', 'C', 'D', 'E', 'F'], '국어': [85, 95, 75, 80, 85, 100], '영어': [80, 90, 95, 70, 75, 85], '수학': [90, 95, 70, 85, 90, 95]} df2 = pd.DataFrame(excel_exam_data2,columns=['학생','국어','영어','수학'] ) df2학생 국어 영어 수학 0 A 85 80 90 1 B 95 90 95 2 C 75 95 70 3 D 80 70 85 4 E 85 75 90 5 F 100 85 95 excel_writer3 = pd.ExcelWriter('C:/myPyCode/data/학생시험성적4.xlsx', engine='xlsxwriter') df1.to_excel(excel_writer3, index=False, sheet_name='중간고사') df2.to_excel(excel_writer3, index=False, sheet_name='기말고사') excel_writer3.save()여러개의 엑셀 파일을 지정하기
excel_data_files = ['C:/myPyCode/data/담당자별_판매량_Andy사원.xlsx', 'C:/myPyCode/data/담당자별_판매량_Becky사원.xlsx', 'C:/myPyCode/data/담당자별_판매량_Chris사원.xlsx']데이터를 통합하기 위해 DataFrame 형태로 변수 생성
한 번에 출력하기
total_data = pd.DataFrame() for f in excel_data_files: df=pd.read_excel(f) total_data=total_data.append(df, ignore_index=True) total_dataC:\Users\Playdata\AppData\Local\Temp\ipykernel_4196\4219662834.py:4: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead. total_data=total_data.append(df, ignore_index=True) C:\Users\Playdata\AppData\Local\Temp\ipykernel_4196\4219662834.py:4: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead. total_data=total_data.append(df, ignore_index=True) C:\Users\Playdata\AppData\Local\Temp\ipykernel_4196\4219662834.py:4: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead. total_data=total_data.append(df, ignore_index=True)제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 A 가 198 123 120 137 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 3 시계 B 나 154 108 155 114 4 구두 B 나 200 223 213 202 5 핸드백 B 나 350 340 377 392 6 시계 C 다 168 102 149 174 7 구두 C 다 231 279 277 292 8 핸드백 C 다 365 383 308 323 for f in excel_data_files: df=pd.read_excel(f) pd.concat([total_data,df], ignore_index=True) total_data제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 A 가 198 123 120 137 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 3 시계 B 나 154 108 155 114 4 구두 B 나 200 223 213 202 5 핸드백 B 나 350 340 377 392 6 시계 C 다 168 102 149 174 7 구두 C 다 231 279 277 292 8 핸드백 C 다 365 383 308 323 많은 파일을 통합할 때 내장모듈 glob 함수 사용 -> 리스트로 받아준다
'*' = 모든, '?' = 한글자import glob # 내장 모듈이기 때문에 바로 import glob.glob('C:/myPyCode/data/담당자별_판매량_*사원.xlsx')>>> ['C:/myPyCode/data\\담당자별_판매량_Andy사원.xlsx', 'C:/myPyCode/data\\담당자별_판매량_Becky사원.xlsx', 'C:/myPyCode/data\\담당자별_판매량_Chris사원.xlsx']excel_data_files1 = glob.glob('C:/myPyCode/data/담당자별_판매량_*사원.xlsx') total_data1 = pd.DataFrame() for f in excel_data_files1: df = pd.read_excel(f) total_data1 = pd.concat([total_data1, df], ignore_index=True) total_data1제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 A 가 198 123 120 137 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 3 시계 B 나 154 108 155 114 4 구두 B 나 200 223 213 202 5 핸드백 B 나 350 340 377 392 6 시계 C 다 168 102 149 174 7 구두 C 다 231 279 277 292 8 핸드백 C 다 365 383 308 323 통합 결과를 엑셀 파일로 저장하기
excel_file_name = 'C:/myPyCode/data/담당자별_판매량_통합.xlsx' excel_total_file_writer = pd.ExcelWriter(excel_file_name, engine = 'xlsxwriter') total_data1.to_excel(excel_total_file_writer, index=False, sheet_name='담당자별_판매량_통합') excel_total_file_writer.save() glob.glob(excel_file_name)>>> ['C:/myPyCode/data/담당자별_판매량_통합.xlsx']3. 엑셀 파일로 읽어온 데이터 다루기
데이터를 추가하고 변경하기
df = pd.read_excel('C:/myPyCode/data/담당자별_판매량_Andy사원.xlsx') df제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 A 가 198 123 120 137 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 df.loc[index_name, column_name] = value
df.loc[2, '4분기'] = 400 df제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 A 가 198 123 120 137 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 400 loc를 이용하여 행을 추가하기
df.loc[3, '제품명'] = '벨트' # 3행에 '제품명'열에 추가 df.loc[3, '담당자'] = 'A' df.loc[3, '지역'] = '가' df.loc[3, '1분기'] = 100 df.loc[3, '2분기'] = 150 df.loc[3, '3분기'] = 200 df.loc[3, '4분기'] = 250 df제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 A 가 198.0 123.0 120.0 137.0 1 구두 A 가 273.0 241.0 296.0 217.0 2 핸드백 A 가 385.0 316.0 355.0 400.0 3 벨트 A 가 100.0 150.0 200.0 250.0 특정 열의 데이터값 전체를 변경
df[column_name] = valuedf['담당자'] = 'Andy' df제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 Andy 가 198.0 123.0 120.0 137.0 1 구두 Andy 가 273.0 241.0 296.0 217.0 2 핸드백 Andy 가 385.0 316.0 355.0 400.0 3 벨트 Andy 가 100.0 150.0 200.0 250.0 새로운 이름으로 저장하기
excel_file_name = 'C:/myPyCode/data/담당자별_판매량_Andy사원_new.xlsx' new_excel_file = pd.ExcelWriter(excel_file_name, engine='xlsxwriter') df.to_excel(new_excel_file, index=False) new_excel_file.save() glob.glob(excel_file_name)>>> ['C:/myPyCode/data/담당자별_판매량_Andy사원_new.xlsx']여러 개의 엑셀 파일에서 데이터 수정하기
import re
re.sub(pattern, repl, string)
string에서 pattern을 찾아내서 대체문자열(repl)로 교체import re file_name = 'C:/myPyCode/data/담당자별_판매량_Andy사원.xlsx' new_file_name = re.sub('.xlsx', '2.xlsx', file_name) new_file_name>>> 'C:/myPyCode/data/담당자별_판매량_Andy사원2.xlsx'여러 개의 엑셀 파일에서 값 변경 후 각각 다른 이름으로 저장하기
# import glob # import re # import pandas as pd # 원하는 문자열이 포함된 파일을 검색해 리스트를 할당한다. excel_data_files1 = glob.glob("C:/myPyCode/data/담당자별_판매량_*사원.xlsx") # 리스트에 있는 엑셀 파일만큼 반복 수행한다. for f in excel_data_files1: # 엑셀 파일에서 DataFrame 형식으로 데이터 가져온다. df = pd.read_excel(f) # 특정 열의 값을 변경한다. if(df.loc[1, '담당자']=='A'): df['담당자']='Andy' elif(df.loc[1, '담당자']=='B'): df['담당자']='Becky' elif(df.loc[1, '담당자']=='C'): df['담당자']='Chris' # 엑셀 파일 이름에서 지정된 문자열 패턴을 찾아서 파일명을 변경한다. f_new = re.sub(".xlsx", "2.xlsx", f) print(f_new) # 수정된 데이터를 새로운 이름의 엑셀 파일로 저장한다. new_excel_file = pd.ExcelWriter(f_new, engine='xlsxwriter') df.to_excel(new_excel_file, index=False) new_excel_file.save()>>> C:/myPyCode/data\담당자별_판매량_Andy사원2.xlsx C:/myPyCode/data\담당자별_판매량_Becky사원2.xlsx C:/myPyCode/data\담당자별_판매량_Chris사원2.xlsx# 원하는 문자열이 포함된 파일을 검색해 리스트를 할당한다. excel_data_files1 = glob.glob("C:/myPyCode/data/담당자별_판매량_*사원.xlsx") name_dict = {'A':'Andy','B':'Becky','C':'Chris'} # 리스트에 있는 엑셀 파일만큼 반복 수행한다. for f in excel_data_files1: # 엑셀 파일에서 DataFrame 형식으로 데이터 가져온다. df = pd.read_excel(f) # 특정 열의 값을 변경한다. df['담당자'] = name_dict[df.loc[1,'담당자']] # 엑셀 파일 이름에서 지정된 문자열 패턴을 찾아서 파일명을 변경한다. f_new = re.sub(".xlsx", "3.xlsx", f) print(f_new) # 수정된 데이터를 새로운 이름의 엑셀 파일로 저장한다. new_excel_file = pd.ExcelWriter(f_new, engine='xlsxwriter') df.to_excel(new_excel_file, index=False) new_excel_file.save()>>> C:/myPyCode/data\담당자별_판매량_Andy사원3.xlsx C:/myPyCode/data\담당자별_판매량_Becky사원3.xlsx C:/myPyCode/data\담당자별_판매량_Chris사원3.xlsx# 원하는 문자열이 포함된 파일을 검색해 리스트를 할당한다. excel_data_files1 = glob.glob("C:/myPyCode/data/담당자별_판매량_*사원.xlsx") init_li = ['A','B','C'] name_li = ['Andy','Becky','Chris'] # 리스트에 있는 엑셀 파일만큼 반복 수행한다. for f in excel_data_files1: # 엑셀 파일에서 DataFrame 형식으로 데이터 가져온다. df = pd.read_excel(f) # 특정 열의 값을 변경한다. df['담당자'] = name_li[init_li.index(df.loc[1,'담당자'])] # 엑셀 파일 이름에서 지정된 문자열 패턴을 찾아서 파일명을 변경한다. f_new = re.sub(".xlsx", "22.xlsx", f) print(f_new) # 수정된 데이터를 새로운 이름의 엑셀 파일로 저장한다. new_excel_file = pd.ExcelWriter(f_new, engine='xlsxwriter') df.to_excel(new_excel_file, index=False) new_excel_file.save()>>> C:/myPyCode/data\담당자별_판매량_Andy사원22.xlsx C:/myPyCode/data\담당자별_판매량_Becky사원22.xlsx C:/myPyCode/data\담당자별_판매량_Chris사원22.xlsxglob.glob("C:/myPyCode/data/담당자별_판매량_*사원??.xlsx") # '?'는 해당 위치에 문자가 '있는' 파일을 찾아준다.>>> ['C:/myPyCode/data\\담당자별_판매량_Andy사원22.xlsx', 'C:/myPyCode/data\\담당자별_판매량_Becky사원22.xlsx', 'C:/myPyCode/data\\담당자별_판매량_Chris사원22.xlsx']엑셀의 필터 기능 수행하기
df = pd.read_excel('C:/myPyCode/data/담당자별_판매량_통합.xlsx') df제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 A 가 198 123 120 137 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 3 시계 B 나 154 108 155 114 4 구두 B 나 200 223 213 202 5 핸드백 B 나 350 340 377 392 6 시계 C 다 168 102 149 174 7 구두 C 다 231 279 277 292 8 핸드백 C 다 365 383 308 323 df['제품명']>>> 0 시계 1 구두 2 핸드백 3 시계 4 구두 5 핸드백 6 시계 7 구두 8 핸드백 Name: 제품명, dtype: objectdf['제품명'] == '핸드백'>>> 0 False 1 False 2 True 3 False 4 False 5 True 6 False 7 False 8 True Name: 제품명, dtype: boolhandbag = df[df['제품명'] == '핸드백'] handbag제품명 담당자 지역 1분기 2분기 3분기 4분기 2 핸드백 A 가 385 316 355 331 5 핸드백 B 나 350 340 377 392 8 핸드백 C 다 365 383 308 323 df = pd.read_excel('C:/myPyCode/data/담당자별_판매량_통합.xlsx') handbag1 = df[df['제품명'].isin(['핸드백'])] handbag1제품명 담당자 지역 1분기 2분기 3분기 4분기 2 핸드백 A 가 385 316 355 331 5 핸드백 B 나 350 340 377 392 8 핸드백 C 다 365 383 308 323 논리합 연산(|)
df[(df['제품명']== '구두') | (df['제품명']== '핸드백')] # df[True] | df[False] 형태로 값이 나오도록 입력하면 된다.제품명 담당자 지역 1분기 2분기 3분기 4분기 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 4 구두 B 나 200 223 213 202 5 핸드백 B 나 350 340 377 392 7 구두 C 다 231 279 277 292 8 핸드백 C 다 365 383 308 323 df[df['제품명'].isin(['구두', '핸드백'])]제품명 담당자 지역 1분기 2분기 3분기 4분기 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 4 구두 B 나 200 223 213 202 5 핸드백 B 나 350 340 377 392 7 구두 C 다 231 279 277 292 8 핸드백 C 다 365 383 308 323 조건을 설정해 원하는 행만 선택하기
df[df['3분기'] >= 250]제품명 담당자 지역 1분기 2분기 3분기 4분기 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 5 핸드백 B 나 350 340 377 392 7 구두 C 다 231 279 277 292 8 핸드백 C 다 365 383 308 323 df[(df['3분기'] >= 250)]제품명 담당자 지역 1분기 2분기 3분기 4분기 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 5 핸드백 B 나 350 340 377 392 7 구두 C 다 231 279 277 292 8 핸드백 C 다 365 383 308 323 논리곱 연산(&)
df[(df['제품명'] == '핸드백') & (df['3분기'] >= 350)]제품명 담당자 지역 1분기 2분기 3분기 4분기 2 핸드백 A 가 385 316 355 331 5 핸드백 B 나 350 340 377 392 원하는 열만 선택하기
df = pd.read_excel('C:/myPyCode/data/담당자별_판매량_Andy사원.xlsx') df제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 A 가 198 123 120 137 1 구두 A 가 273 241 296 217 2 핸드백 A 가 385 316 355 331 출력하려는 열의 헤더(header)를 리스트 형식으로 지정해 가져오기
df[['제품명','1분기', '2분기','3분기', '4분기']] # 리스트로 안에서 한번 더 씌워줘야 한다. 바깥 []는 위치값에 쓰이는 괄호.제품명 1분기 2분기 3분기 4분기 0 시계 198 123 120 137 1 구두 273 241 296 217 2 핸드백 385 316 355 331 행과 열의 위치를 숫자로 지정해 원하는 위치의 데이터만 선택하는 방법
DataFrame_data.iloc[row_num, col_num]df.iloc[:,[0,3,4,5,6]] # 모든 행, 선택 열제품명 1분기 2분기 3분기 4분기 0 시계 198 123 120 137 1 구두 273 241 296 217 2 핸드백 385 316 355 331 df.iloc[[0,2],:] # 선택 행, 모든 열제품명 담당자 지역 1분기 2분기 3분기 4분기 0 시계 A 가 198 123 120 137 2 핸드백 A 가 385 316 355 331 엑셀 데이터 계산하기
df = pd.read_excel('C:/myPyCode/data/담당자별_판매량_통합.xlsx') handbag = df[(df['제품명']== '핸드백')] handbag제품명 담당자 지역 1분기 2분기 3분기 4분기 2 핸드백 A 가 385 316 355 331 5 핸드백 B 나 350 340 377 392 8 핸드백 C 다 365 383 308 323 handbag.sum(axis=1)>>> 2 1387 5 1459 8 1379 dtype: int64DataFrame 형태로 데이터 생성
handbag_sum = pd.DataFrame(handbag.sum(axis=1), columns = ['연간판매량']) handbag_sum연간판매량 2 1387 5 1459 8 1379 handbag_total = handbag.join(handbag_sum) # 맨 뒷 '열'에 추가할 때 join handbag_total제품명 담당자 지역 1분기 2분기 3분기 4분기 연간판매량 2 핸드백 A 가 385 316 355 331 1387 5 핸드백 B 나 350 340 377 392 1459 8 핸드백 C 다 365 383 308 323 1379 연간판매량을 기준으로 오름차순으로 정렬
handbag_total.sort_values(by='연간판매량', ascending=True)제품명 담당자 지역 1분기 2분기 3분기 4분기 연간판매량 8 핸드백 C 다 365 383 308 323 1379 2 핸드백 A 가 385 316 355 331 1387 5 핸드백 B 나 350 340 377 392 1459 연간판매량을 기준으로 내림차순으로 정렬
handbag_total.sort_values(by='연간판매량', ascending=False)제품명 담당자 지역 1분기 2분기 3분기 4분기 연간판매량 5 핸드백 B 나 350 340 377 392 1459 2 핸드백 A 가 385 316 355 331 1387 8 핸드백 C 다 365 383 308 323 1379 열 데이터의 합계 구하기
handbag_total.sum() # 행-열이 회전되어 나온다. (Series 타입)>>> 제품명 핸드백핸드백핸드백 담당자 ABC 지역 가나다 1분기 1100 2분기 1039 3분기 1040 4분기 1046 연간판매량 4225 dtype: objecthandbag_sum2 = pd.DataFrame(handbag_total.sum(), columns=['합계']) handbag_sum2 # 데이터 프레임으로 만들어준다.합계 제품명 핸드백핸드백핸드백 담당자 ABC 지역 가나다 1분기 1100 2분기 1039 3분기 1040 4분기 1046 연간판매량 4225 handbag_total2 = handbag_total.append(handbag_sum2.T) # T로 회전시켜서 기존 데이터프레임에 붙여준다. handbag_total2 # 맨 뒷 행에 붙여줄 때는 append제품명 담당자 지역 1분기 2분기 3분기 4분기 연간판매량 2 핸드백 A 가 385 316 355 331 1387 5 핸드백 B 나 350 340 377 392 1459 8 핸드백 C 다 365 383 308 323 1379 합계 핸드백핸드백핸드백 ABC 가나다 1100 1039 1040 1046 4225 handbag_total2.loc['합계', '제품명'] = '핸드백' handbag_total2.loc['합계', '담당자'] = '전체' handbag_total2.loc['합계', '지역'] = '전체' handbag_total2제품명 담당자 지역 1분기 2분기 3분기 4분기 연간판매량 2 핸드백 A 가 385 316 355 331 1387 5 핸드백 B 나 350 340 377 392 1459 8 핸드백 C 다 365 383 308 323 1379 합계 핸드백 전체 전체 1100 1039 1040 1046 4225 import pandas as pd # 엑셀 파일을 pandas의 DataFrame 형식으로 읽어온다. df = pd.read_excel('C:/myPyCode/data/담당자별_판매량_통합.xlsx') # 제품명 열에서 핸드백이 있는 행만 선택한다. product_name = '핸드백' handbag = df[(df['제품명']== product_name)] # 행별로 합계를 구하고 마지막 열 다음에 추가한다. handbag_sum = pd.DataFrame(handbag.sum(axis=1), columns = ['연간판매량']) handbag_total = handbag.join(handbag_sum) # 열별로 합해 분기별 합계와 연간판매량 합계를 구하고 마지막 행 다음에 추가한다. handbag_sum2 = pd.DataFrame(handbag_total.sum(), columns=['합계']) handbag_total2 = pd.concat([handbag_total, handbag_sum2.T]) # 지정된 항목의 문자열을 변경한다. handbag_total2.loc['합계', '제품명'] = product_name handbag_total2.loc['합계', '담당자'] = '전체' handbag_total2.loc['합계', '지역'] = '전체' # 결과를 확인한다. handbag_total2제품명 담당자 지역 1분기 2분기 3분기 4분기 연간판매량 2 핸드백 A 가 385 316 355 331 1387 5 핸드백 B 나 350 340 377 392 1459 8 핸드백 C 다 365 383 308 323 1379 합계 핸드백 전체 전체 1100 1039 1040 1046 4225 13.4 엑셀 데이터의 시각화
그래프를 엑셀 파일에 넣기
데이터프레임 생성
import matplotlib.pyplot as plt import pandas as pd sales = {'시간': [9, 10, 11, 12, 13, 14, 15], '제품1': [10, 15, 12, 11, 12, 14, 13], '제품2': [9, 11, 14, 12, 13, 10, 12]} df = pd.DataFrame(sales, index = sales['시간'], columns = ['제품1', '제품2']) df.index.name = '시간' #index 라벨 추가 df제품1 제품2 시간 9 10 9 10 15 11 11 12 14 12 11 12 13 12 13 14 14 10 15 13 12 '시간' 데이터는 x축으로 '제품 1'과 '제품 2'의 생산량은 y축으로 지정한 그래프를 생성
import matplotlib matplotlib.rcParams['font.family'] = 'Malgun Gothic'# '맑은 고딕'으로 설정 matplotlib.rcParams['axes.unicode_minus'] = False product_plot = df.plot(grid = True, style = ['-*', '-o'], title='시간대별 생산량') product_plot.set_ylabel("생산량") image_file = 'C:/myPyCode/figures/fig_for_excel1.png' # 이미지 파일 경로 및 이름 plt.savefig(image_file, dpi = 400) # 그래프를 이미지 파일로 저장 plt.show()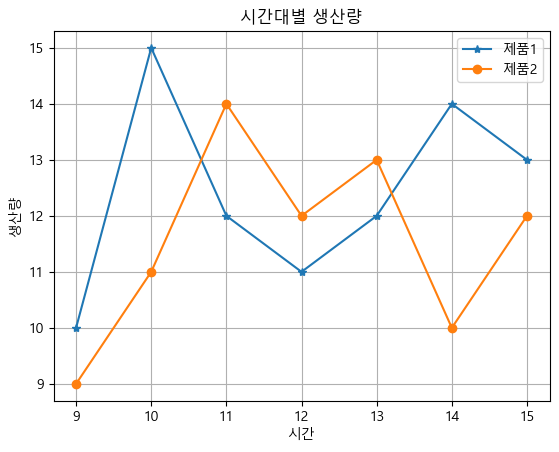
import pandas as pd # (1) pandas의 ExcelWriter 객체 생성 excel_file = 'C:/myPyCode/data/data_image_to_excel.xlsx' excel_writer = pd.ExcelWriter(excel_file, engine='xlsxwriter') # (2) DataFrame 데이터를 지정된 엑셀 시트(Sheet)에 쓰기 df.to_excel(excel_writer, index=True, sheet_name='Sheet1') # (3) ExcelWriter 객체에서 워크시트(worksheet) 객체 생성 worksheet = excel_writer.sheets['Sheet1'] # (4) 워크시트에 차트가 들어갈 [위치]를 지정해 이미지 넣기 worksheet.insert_image('D2', image_file, {'x_scale': 0.7, 'y_scale': 0.7}) # 이미지 파일 삽입하기 # worksheet.insert_image(1, 3, image_file, {'x_scale': 0.7, 'y_scale': 0.7}) # 행과 열 값 # (5) ExcelWriter 객체를 닫고 엑셀 파일 출력 excel_writer.save()엑셀 차트 만들기
엑셀에서 그릴 수 있는 차트 유형
지정 가능한 차트 유형 엑셀 차트 유형 area 영역형 차트 bar 가로 막대형 차트 column 세로 막대형 차트 line 꺾은 선형 차트 pie 원형 차트 doughnut 도넛형 차트 scatter 분산형 차트 stock 주식형 차트 radar 방사형 차트 # (1) pandas의 ExcelWriter 객체 생성 excel_chart = pd.ExcelWriter('C:/myPyCode/data/data_chart_in_excel.xlsx', engine='xlsxwriter') # (2) DataFrame 데이터를 지정된 엑셀 시트(Sheet)에 쓰기 df.to_excel(excel_chart, index=True, sheet_name='Sheet1') # (3) ExcelWriter 객체에서 워크북(workbook)과 워크시트(worksheet) 객체 생성 workbook = excel_chart.book worksheet = excel_chart.sheets['Sheet1'] # (4) 차트 객체 생성(원하는 차트의 종류 지정) chart = workbook.add_chart({'type': 'line'}) # (5) 차트 생성을 위한 데이터값의 범위 지정 chart.add_series({'values': '=Sheet1!$B$2:$B$8'}) chart.add_series({'values': '=Sheet1!$C$2:$C$8'}) # (6) 워크시트에 차트가 들어갈 위치를 지정해 차트 넣기 worksheet.insert_chart('D2', chart) # (7) ExcelWriter 객체를 닫고 엑셀 파일 출력 excel_chart.save()# (1) pandas의 ExcelWriter 객체 생성 excel_chart = pd.ExcelWriter('./data/data_chart_in_excel.xlsx', engine='xlsxwriter') # (2) DataFrame 데이터를 지정된 엑셀 시트(Sheet)에 쓰기 df2 = df.copy() df.to_excel(excel_chart, index=True, sheet_name='Sheet1') df2.to_excel(excel_chart, index=True, sheet_name='Sheet2') # (3) ExcelWriter 객체에서 워크북(workbook)과 워크시트(worksheet) 객체 생성 workbook = excel_chart.book worksheet1 = excel_chart.sheets['Sheet1'] worksheet2 = excel_chart.sheets['Sheet2'] # (4) 차트 객체 생성(원하는 차트의 종류 지정) chart1 = workbook.add_chart({'type': 'line'}) chart2 = workbook.add_chart({'type': 'line'}) # (5) 차트 생성을 위한 데이터값의 범위 지정 chart1.add_series({'values': '=Sheet1!$B$2:$B$8'}) chart1.add_series({'values': '=Sheet1!$C$2:$C$8'}) chart2.add_series({'values': '=Sheet2!$B$2:$B$8', 'categories': '=Sheet2!$A$2:$A$8', 'name': '=Sheet2!$B$1',}) chart2.add_series({'values': '=Sheet2!$C$2:$C$8', 'categories': '=Sheet2!$A$2:$A$8', 'name': '=Sheet2!$C$1',}) # (6) 워크시트에 차트가 들어갈 위치를 지정해 차트 넣기 worksheet1.insert_chart('D2', chart1) worksheet2.insert_chart('D2', chart2) # (7) ExcelWriter 객체를 닫고 엑셀 파일 출력 excel_chart.save()# (1) pandas의 ExcelWriter 객체 생성 excel_chart = pd.ExcelWriter('./data/data_chart_in_excel.xlsx', engine='xlsxwriter') # (2) DataFrame 데이터를 지정된 엑셀 시트(Sheet)에 쓰기 df2 = df.copy() df3 = df.copy() df.to_excel(excel_chart, index=True, sheet_name='Sheet1') df2.to_excel(excel_chart, index=True, sheet_name='Sheet2') df3.to_excel(excel_chart, index=True, sheet_name='Sheet3') # (3) ExcelWriter 객체에서 워크북(workbook)과 워크시트(worksheet) 객체 생성 workbook = excel_chart.book worksheet1 = excel_chart.sheets['Sheet1'] worksheet2 = excel_chart.sheets['Sheet2'] worksheet3 = excel_chart.sheets['Sheet3'] # (4) 차트 객체 생성(원하는 차트의 종류 지정) chart1 = workbook.add_chart({'type': 'line'}) chart2 = workbook.add_chart({'type': 'line'}) chart3 = workbook.add_chart({'type': 'line'}) # (5) 차트 생성을 위한 데이터값의 범위 지정 chart1.add_series({'values': '=Sheet1!$B$2:$B$8'}) chart1.add_series({'values': '=Sheet1!$C$2:$C$8'}) chart2.add_series({'values': '=Sheet2!$B$2:$B$8', 'categories': '=Sheet2!$A$2:$A$8', 'name': '=Sheet2!$B$1',}) chart2.add_series({'values': '=Sheet2!$C$2:$C$8', 'categories': '=Sheet2!$A$2:$A$8', 'name': '=Sheet2!$C$1',}) chart3.add_series({'values': '=Sheet3!$B$2:$B$8', 'categories': '=Sheet3!$A$2:$A$8', 'name': '=Sheet3!$B$1',}) chart3.add_series({'values': '=Sheet3!$C$2:$C$8', 'categories': '=Sheet3!$A$2:$A$8', 'name': '=Sheet3!$C$1',}) # (5-1) 엑셀 차트에 x, y축 라벨과 제목 추가 chart3.set_title ({'name': '시간대별 생산량'}) chart3.set_x_axis({'name': '시간'}) chart3.set_y_axis({'name': '생산량'}) # (6) 워크시트에 차트가 들어갈 위치를 지정해 차트 넣기 worksheet1.insert_chart('D2', chart1) worksheet2.insert_chart('D2', chart2) worksheet3.insert_chart('D2', chart3) # (7) ExcelWriter 객체를 닫고 엑셀 파일 출력 excel_chart.save()'[플레이데이터]' 카테고리의 다른 글
[PlayData - Day 14] 웹 API (0) 2023.01.12 [PlayData - Day 13] BeautifulSoup - 웹 스크레이핑(Web Scraping) (0) 2023.01.09 [PlayData - Day 11] Matplotlib - 데이터 시각화 (1) 2023.01.06 [PlayData - Day 10] Pandas - 구조적 데이터 표시와 처리 (0) 2023.01.06 [PlayData - Day 9] Numpy - 배열 데이터 다루기 (1) 2023.01.06